캐시메모리란?
 https://www.xtremegaminerd.com/types-of-cache-memory/
https://www.xtremegaminerd.com/types-of-cache-memory/
속도가 빠른 장치(CPU)와 느린 장치(메모리) 사이에서 속도차이에 따른 병목현상을 줄이기 위한 범용 메모리입니다.
병목현상 : 어떤 시스템 내 데이터의 집중적인 사용으로 인해, 전체 시스템에 절대적 영향을 미치는 부분의
사용 빈도가 늘어나 그 부분의 성능이 저하되어 전체 시스템이 마비되는 현상을 의미
입출력 데이터를 버퍼링하여 Memory 접근 없이 빠른 입출력 제공합니다.
최근에 사용된 데이터나 자주 사용되는 데이터를 임시로 저장해두죠.
캐시메모리는 빠르지만 용량이 적고 비싸다는 단점이 있습니다.
대부분의 프로그램은 한번 사용한 데이터를 다시 사용할 가능성이 높고
그 주변의 데이터도 곧 사용될 가능성이 높은 데이터 지역성을 가지고 있습니다.
1. 공간적 지역성 : CPU가 요청한 주소 지점에 인접한 데이터들이 앞으로 참조될 가능성이 높은 현상
2. 시간적 지역성 : 최근 사용된 데이터, 변수가 재사용될 가능성이 높은 현상
3. 순차적 지역성 : 데이터가 기억장치에 저장된 순서대로 순차적으로 인출 되고 실행될 가능성이 높은 현상
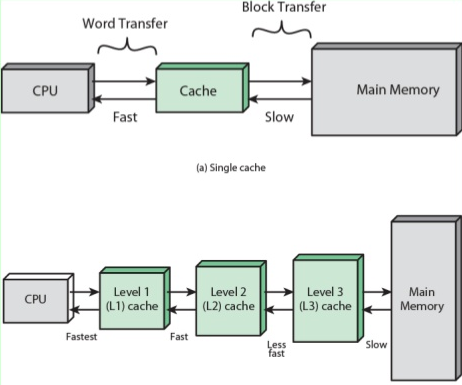
캐쉬를 보다보면 L1, L2 용어가 나옵니다.
L1에는 I-Cache(Instruction Cache)와 D-Cache(Data Cache)가 따로 있고 L2에는 구분없이 하나의 캐시로 구성됩니다.
보통 CPU에서 L1부터 빠르게 접근하며 속도가 빠릅니다.
L1에 찾고자하는 데이터가 없으면 L2에 접근하여 데이터를 찾습니다.
속도는 L1>L2>RAM입니다.
L3는 있는 경우도 있고 없는 경우도 있습니다.
여기서 보통 명령어(Instruction)는 공간 지역성이 높고 데이터는 시간 지역성이 높습니다.
CPU가 캐시에서 데이터를 찾는데 데이터가 없다면 이를 캐시 미스라고 합니다.
1. Compulsory miss : 해당 메모리 주소를 처음 부르는 경우
2. Conflict miss : 서로 다른 데이터가 같은 캐시 메모리 주소에 할당되는 경우
3. Capacity miss : 캐시 메모리에 공간이 부족해서 나는 경우
적중률(Hit Ratio) : 얼마나 캐시를 통해서 데이터를 잘 찾았는지의 정도
버퍼메모리란(Buffer)?
버퍼메모리도 캐시메모리랑 비슷한 역할을 합니다. 두 장치간의 속도 차이를 극복하기 위해 사용하죠.
간단히 말하면 일시적인 데이터 저장소로 이용하는 기억 장치입니다.
흠 표현하자면 캐시는 작업속도를 빠르게 해주고
버퍼는 빠른 쪽에서 데이터가 느린 쪽으로 갈 때 데이터 손실이 나지 않게 합니다.
캐시는 CPU가 놀고있는 시간을 줄이고 버퍼는 주변기기가 놀고있는 시간을 줄입니다.
그리고 버퍼는 순차적으로 데이터를 접근하고 캐시는 데이터에 직접적으로 접근할 수 있습니다.